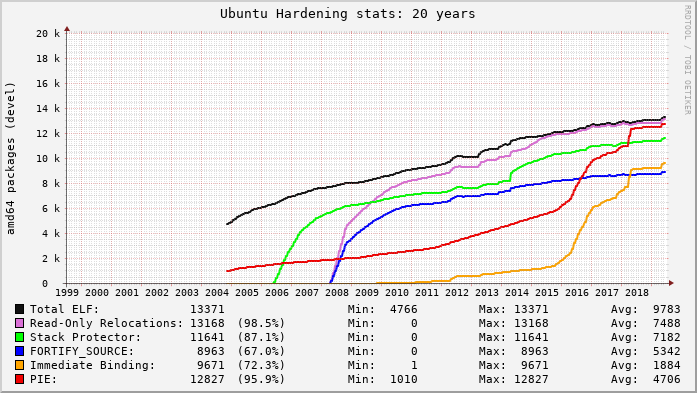
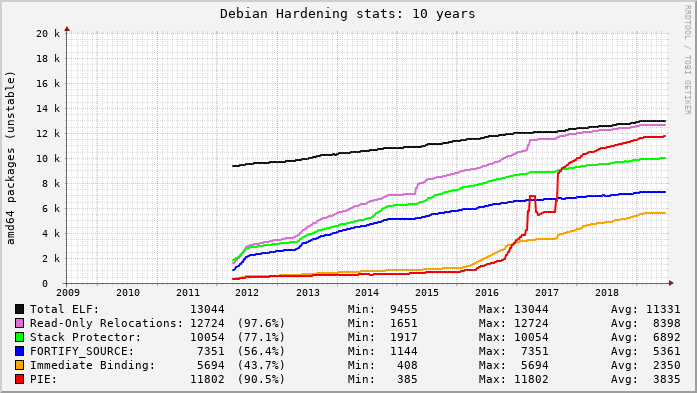
As part of the continuing work to replace 1-element arrays in the Linux kernel, it’s very handy to show that a source change has had no executable code difference. For example, if you started with this:
struct foo {
unsigned long flags;
u32 length;
u32 data[1];
};
void foo_init(int count)
{
struct foo *instance;
size_t bytes = sizeof(*instance) + sizeof(u32) * (count - 1);
...
instance = kmalloc(bytes, GFP_KERNEL);
...
};
And you changed only the struct definition:
- u32 data[1]; + u32 data[];
The bytes calculation is going to be incorrect, since it is still subtracting 1 element’s worth of space from the desired count. (And let’s ignore for the moment the open-coded calculation that may end up with an arithmetic over/underflow here; that can be solved separately by using the struct_size() helper or the size_mul(), size_add(), etc family of helpers.)
The missed adjustment to the size calculation is relatively easy to find in this example, but sometimes it’s much less obvious how structure sizes might be woven into the code. I’ve been checking for issues by using the fantastic diffoscope tool. It can produce a LOT of noise if you try to compare builds without keeping in mind the issues solved by reproducible builds, with some additional notes. I prepare my build with the “known to disrupt code layout” options disabled, but with debug info enabled:
$ KBF="KBUILD_BUILD_TIMESTAMP=1980-01-01 KBUILD_BUILD_USER=user KBUILD_BUILD_HOST=host KBUILD_BUILD_VERSION=1"
$ OUT=gcc
$ make $KBF O=$OUT allmodconfig
$ ./scripts/config --file $OUT/.config \
-d GCOV_KERNEL -d KCOV -d GCC_PLUGINS -d IKHEADERS -d KASAN -d UBSAN \
-d DEBUG_INFO_NONE -e DEBUG_INFO_DWARF_TOOLCHAIN_DEFAULT
$ make $KBF O=$OUT olddefconfig
Then I build a stock target, saving the output in “before”. In this case, I’m examining drivers/scsi/megaraid/:
$ make -jN $KBF O=$OUT drivers/scsi/megaraid/ $ mkdir -p $OUT/before $ cp $OUT/drivers/scsi/megaraid/*.o $OUT/before/
Then I patch and build a modified target, saving the output in “after”:
$ vi the/source/code.c $ make -jN $KBF O=$OUT drivers/scsi/megaraid/ $ mkdir -p $OUT/after $ cp $OUT/drivers/scsi/megaraid/*.o $OUT/after/
And then run diffoscope:
$ diffoscope $OUT/before/ $OUT/after/
If diffoscope output reports nothing, then we’re done. 🥳
Usually, though, when source lines move around other stuff will shift too (e.g. WARN macros rely on line numbers, so the bug table may change contents a bit, etc), and diffoscope output will look noisy. To examine just the executable code, the command that diffoscope used is reported in the output, and we can run it directly, but with possibly shifted line numbers not reported. i.e. running objdump without --line-numbers:
$ ARGS="--disassemble --demangle --reloc --no-show-raw-insn --section=.text"
$ for i in $(cd $OUT/before && echo *.o); do
echo $i
diff -u <(objdump $ARGS $OUT/before/$i | sed "0,/^Disassembly/d") \
<(objdump $ARGS $OUT/after/$i | sed "0,/^Disassembly/d")
done
If I see an unexpected difference, for example:
- c120: movq $0x0,0x800(%rbx) + c120: movq $0x0,0x7f8(%rbx)
Then I'll search for the pattern with line numbers added to the objdump output:
$ vi <(objdump --line-numbers $ARGS $OUT/after/megaraid_sas_fp.o)
I'd search for "0x0,0x7f8", find the source file and line number above it, open that source file at that position, and look to see where something was being miscalculated:
$ vi drivers/scsi/megaraid/megaraid_sas_fp.c +329
Once tracked down, I'd start over at the "patch and build a modified target" step above, repeating until there were no differences. For example, in the starting example, I'd also need to make this change:
- size_t bytes = sizeof(*instance) + sizeof(u32) * (count - 1); + size_t bytes = sizeof(*instance) + sizeof(u32) * count;
Though, as hinted earlier, better yet would be:
- size_t bytes = sizeof(*instance) + sizeof(u32) * (count - 1); + size_t bytes = struct_size(instance, data, count);
But sometimes adding the helper usage will add binary output differences since they're performing overflow checking that might saturate at SIZE_MAX. To help with patch clarity, those changes can be done separately from fixing the array declaration.
© 2022 - 2023, Kees Cook. This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 License.